What is AutoML and how can it be applied to practice?
AutoML helps domain experts to harness the power of artificial intelligence and machine learning to use data to support their work and automate routine tasks.
Automated machine learning (AutoML) is a generic term for various technologies that try to find the best possible machine learning pipeline to solve a problem. In machine learning (ML) without automation, data scientists explore different machine learning pipelines and, based on the results, choose the best performing pipelines (or keep on improving the models based on analysis). In AutoML a computer tests different machine learning pipelines and, based on the results, it keeps iterating to find the best possible one. So, in essence, AutoML automates the laborious work of finding the best possible pipeline (and all the necessary parameters).
AutoML has mainly been used for supervised learning applications, i.e., regression and classification, but it can also be used for unsupervised learning and reinforcement learning. AutoML supports various data modalities such as structured data, text, images, sound, and temporal and multimodal data, and it can therefore be used in many different applications.
A user does not necessarily need to understand ML to use AutoML, meaning AutoML could potentially make anyone a citizen data scientist that can harness the power of machine learning to help them in their daily tasks. This could have a huge impact on how much machine learning is used to automate and support decision-making. Domain experts have the best knowledge and intuition about what they need to predict and what kind of data can be used to make such predictions to automate laborious tasks. Therefore, it is logical to let domain experts teach computers to help them to automate routine tasks without the need for a data scientist. This avoids the knowledge transfer gap – and obviously removes the need to have a data scientist. Seeing the impact directly motivates domain experts to train computers, i.e., to provide carefully labelled data. It is critical because ML including AutoML needs high-quality training data.
In this post, we study how AutoML could be used in practical applications and discuss its limitations.
Experimental setup for an AutoML use case
To get a good understanding of the current status of AutoML tools, a few experiments were carried out. Instead of running toy data examples such as MNIST or Boston house price predictions, which are being used in universities to teach the basics of machine learning, we wanted to test AutoML in a more realistic environment.
In Kaggle, thousands of human experts compete against each other in various tasks using data derived from real live systems. Therefore, Kaggle provides realistic datasets, and in addition, top-performing solutions can be considered state of the art.
Based on our experience, the three most common use cases for ML (for supervised learning) are structured data classification and regression, text classification and image classification. For this experiment we studied a couple of popular open-source libraries and cloud services for AutoML, then compared their performance to the top results in Kaggle competitions.
We chose to use text classification for our experiment because it is one of the most common and challenging problems in machine learning. Google’s JigSaw organised a Toxic Comments Classification Challenge in Kaggle three years ago. It was very popular and a challenging task, so we thought that it would be a good experiment for this study. In the challenge, the goal is to detect different types of toxicity like threats, obscenity, insults and identity-based hate in Wikipedia’s edit page discussion comments.
Open source AutoML tools
AutoKeras
AutoKeras is a framework that searches for an optimal neural network architecture (and its hyperparameters) using neural architecture search (NAS) and Bayesian optimisation. AutoKeras is built on Keras and it uses Tensorflow as its backend to run computations. The benefit of having Tensorflow as the backend is that it is possible to use graphics processing units (GPUs) and even distribute computations to multiple GPUs.
AutoKeras supports structured data, text, images and multimodal data and it can be used for classification and regression of one or multiple outputs. Therefore, it can be used in many ML applications out of the box. It can also be extended rather easily for unsupervised learning applications.
AutoGluon
AutoGluon is built on Apache MXNet. AutoGluon supports stacking traditional scikit-learn pipelines together and also supports NAS. It can therefore efficiently find high-accuracy models for structured data and can also be used in more challenging cases such as text and image classification.
AutoKeras vs. AutoGluon – a comparison
In the following table, we compare the features of AutoKeras and AutoGluon.
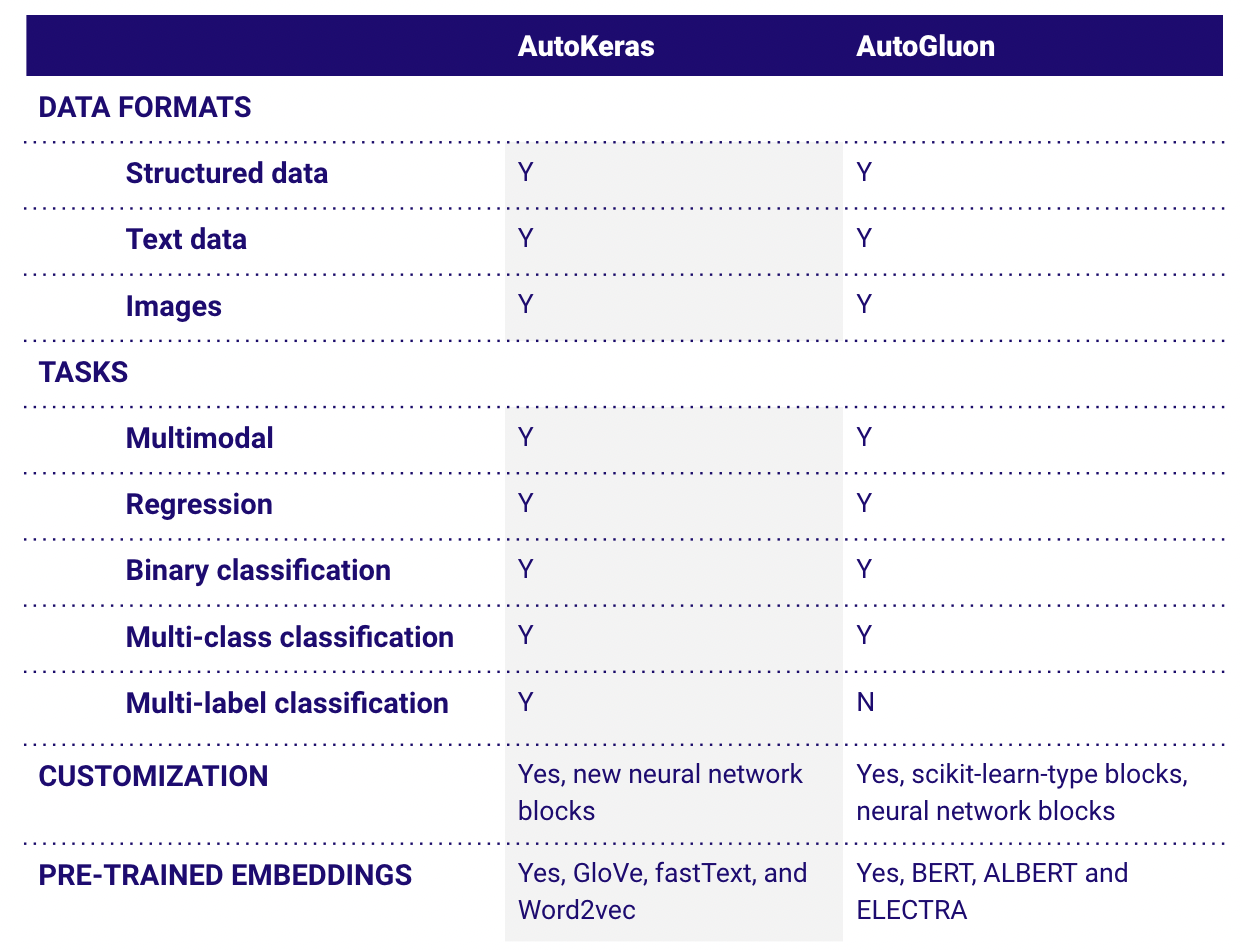
One of the biggest drawbacks of AutoGluon is that it does not support multi-label or multi-label classification, meaning multiple models need to be trained for a multi-label classification task.
JigSaw Toxic Comments Classification Challenge with AutoKeras and AutoGluon
AutoKeras
Embedded content: https://gist.github.com/teemukinnunen/d519813deccbd15e6e526cb1ecd5afc0.js
AutoGluon
Embedded content: https://gist.github.com/teemukinnunen/acccf2e6d96559392b0dfdb3fefa329e.js
As you can see, it is possible to train an AutoML model using AutoKeras with just a couple of lines of code. Since AutoGluon does not support multi-label classification, we had to implement a new class that consists of multiple AutoML text classification models (one for each label). It is not the most efficient way to do multi-label classification, because instead of training a single model, you need to train a single model for each label. Also, in inference, you need to run all the models once for each label.
AutoML as a service
All the major cloud vendors provide managed AutoML services. When using AutoML in a managed cloud service, you don’t need to worry about the infrastructure. It is enough to convert the training data into an appropriate format and upload it to the cloud service.
Amazon Web Services (AWS) bundled all their machine learning-related services into AWS Sagemaker. In AWS Sagemaker you can label data, explore data in hosted notebooks, and train models both with and without AutoML using Autopilot.
Microsoft provides a similar setup in their Azure ML workspace. Their AutoML solution is called Automated ML.
Google renewed its ML solutions recently. Now, all their machine learning tools are under the Vertex AI brand. Google Vertex AI also provides tools for data labelling, running hosted notebooks to explore data, and training and deploying custom ML and AutoML models.
On a high level and feature wise, all the cloud vendors have pretty much the same offering. For this study, we focused on Google AutoML.
Results of the experiment
In order to get a good understanding of AutoML, we carried out experiments using the Jigsaw Toxic Comments challenge in Kaggle. Naturally, the results of a single experiment cannot be generalised to other AutoML applications – and only barely to other text classification tasks. However, they give a glimpse of what you can expect from open source and cloud vendor AutoML tools.

AutoGluon performs the worst in the experiment. The reason could be that it does not support multi-label classification out of the box, and we had to combine multiple binary classification models together. AutoKeras and Google Vertex AI AutoML perform virtually the same, with AutoKeras performing slightly better.
Running times and costs
Two important aspects in AutoML and the data science process are iteration speed and infrastructure costs. This is especially true if you want to deploy ML to a wider audience as cost and iteration speed could become bottlenecks.

It took ~5 hours to train a model using GCP Vertex AI AutoML and ~10 hours to train a model using AutoKeras (10 models, P100 GPU, 4 CPU cores, 16 GB ram). Training a model using GCP AutoML costs 15 USD, but making a prediction cost 750 USD: training models and running inference using AutoKeras and Notebooks in GCP cost a bit over 20 USD.
Development experience
It is easy to get started with cloud services if the data is already in a proper format. However, based on our experience, sometimes it is easier to use open source libraries than cloud services because their format for input data can be tricky in practice. For example, the CSV format is not suitable for text where a single document can contain multiple lines. JSON is more appropriate, but then converting from table format into nested JSONL is not trivial either, especially when the documentation is outdated and inaccurate.
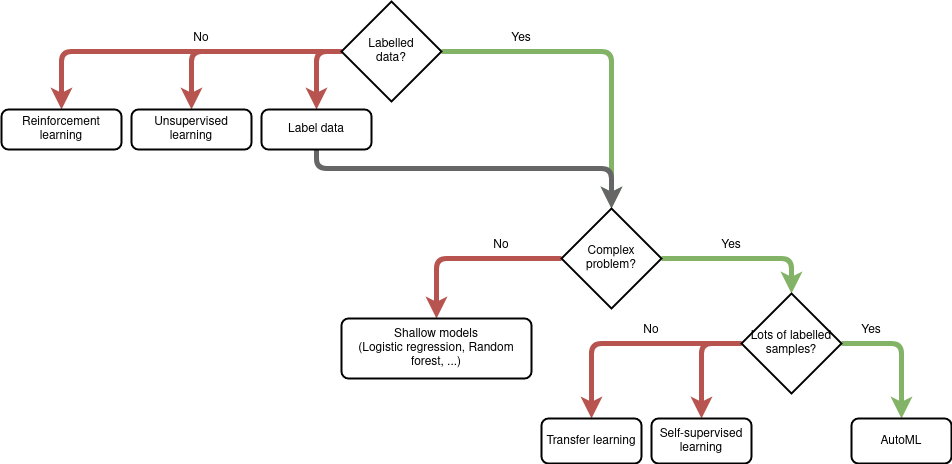
When to use AutoML
AutoML can be used for supervised, unsupervised and reinforcement learning; however, the most successful applications in AutoML use supervised learning where researchers and data scientists have achieved encouraging results. Because of this we recommend AutoML is used for supervised learning rather than unsupervised or reinforcement learning.
If the data is structured, it is most likely that a simple shallow model such as logistic regression, Support Vector Machine (SVM) or Random Forest will work just as well as more complex deep neural networks. In this case you should use shallow learning and find the best model using a standard model selection approach to save computational resources and time.
When using AutoML for unstructured data for a classification or regression task using supervised learning, lots of labelled training samples are needed or AutoML will not be able to train complex models. In such a case, you should use transfer learning or train a model for feature extraction using self-supervised learning, then finetune the model for the specific task with labelled data.
Limitations of AutoML
One limitation of AutoML is its slow iteration speed. In a typical data science project, a labeled training set evolves throughout the project. Training a model using AutoML takes hours or even days, which is not ideal for a quick, iterative process.
AutoML is reaching SOTA and even outperforms human experts in some domains, for example in image recognition when there is a large, labeled training set available and enough computational resources and time available. For smaller datasets and with a limited amount of time and resources available, it might be better to use human expertise and intuition to design neural network architectures. Not all AutoML libraries support transfer learning or the use of pre-trained transformers, which can be essential for working with small amounts of data.
Conclusions
The AutoML tools tested in this study are easy to use and robust enough to be used in real-world applications.
Cloud solutions make experimenting with AutoML easy because you don’t need to manage infrastructure or write code. However, cloud services don’t support all use cases and as they work more like black boxes, using them can become surprisingly expensive.
The open source AutoML tools tested here seem to perform at the same level if not better than the cloud solutions. They are more flexible and can therefore be used in virtually any use case. Of course, it would take more effort and maybe need the help of a data scientist. Also, when using open source tools, you need to manage the infrastructure to train the AutoML models and to make predictions. For a data scientist, that gives more freedom and flexibility, but for a citizen data scientist, it can be too challenging.
- In a nutshell
- What is AutoML?
- AutoML or automated machine learning is a generic term for various technologies that try to find the best possible machine learning pipeline to solve a problem. AutoML means that a computer tests different machine learning pipelines and, based on the results, it keeps iterating to find the best possible one.
- When is AutoML used most often?
- AutoML is primarily used for supervised learning applications, i.e., regression and classification. Automl techniques can also be used for unsupervised learning and reinforcement learning.
- What are some of the common use cases for ML?
- Based on our experience, the three most common use cases for ML (for supervised learning) are structured data classification and regression, text classification and image classification.
- What are some of the best AutoML tools?
- The best AutoML tool depends on the problem to be solved and the nature of the learning application. Common open source AutoML tools include AutoKeras and AutoGluon. We have compared the features of these tools comprehensively for different data formats and machine learning tasks.
 Teemu KinnunenData Scientist
Teemu KinnunenData Scientist





