As a seasoned consultant, I have a love & hate relationship with data. It can inspire creativity, but it can also kill it. We’ve all heard the stories about the Google Creative Director resigning over testing 41 shades of blue or Jeff Bezos mentioning all his best decisions involved intuition and gut, not analysis. Of course, we need data and insights to create meaningful services, so that aim should be to find the balance between data-inspired, data-informed, and data-driven ways of working. In the field of design, we are looking for new ways to incorporate data into our process, and in some cases, AI can even do the job of designing. For example, here is how Airbnb has used to optimize the layout of the article.
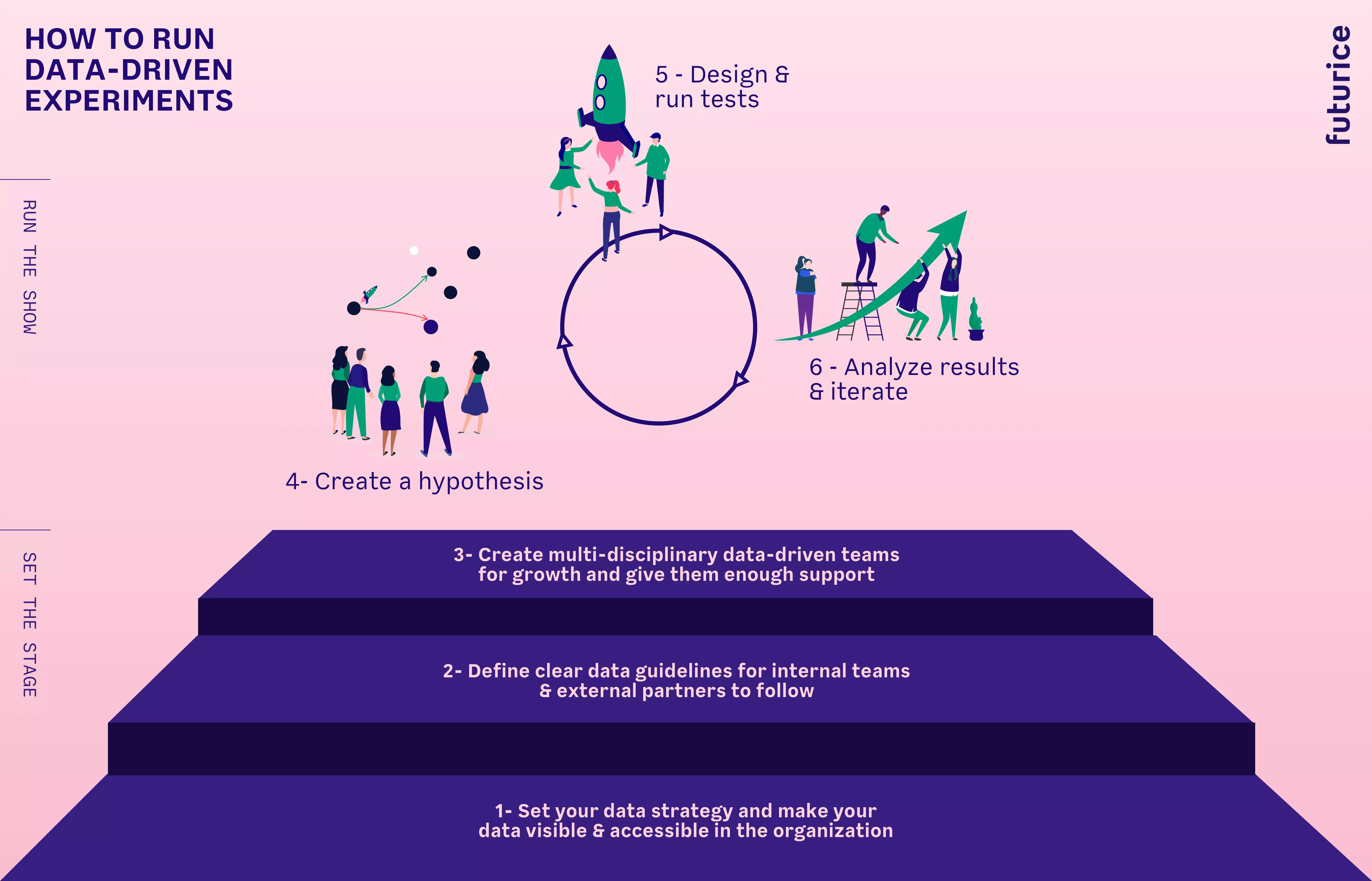
How can we get the most out of using data when developing new products and services or engaging in other transformation efforts? Based on my relationship to data and my experiences as a designer in data-centric digital transformation projects, I’ve formulated a relatively simple six-step process you can use to ensure the best possible result. The first three steps are at the organization level, while the later ones are at the team level.
 Click here for full size image
Click here for full size image
SETTING THE STAGE (ORGANIZATIONAL LEVEL)
1 - Set your data strategy and make data visible and accessible in the organization
First, you need a clear data architecture map that indicates how data is exchanged between services, legacy systems, etc. This map is crucial for defining the current situation and future data strategy & governance.
Second, many organizations suffer from silo structures, making data less visible and harder to access across different products. Start by creating a data catalog both internal and external stakeholders can use*. Catalogue will help you to understand what data is missing and support your strategy. The catalog shows what data is available and from where: customer demographic and purchase behaviour data from legacy systems, service usage data, etc. The data catalog could, for example, deal in detail with attributes like:
- service
- data name
- data type
- source
- classification
- refresh rate
- data unit
- data format
- API availability
- business owner
- ICT contact
...and so on.
The catalog is used in new business ideation sessions across many products & services as well as for creating quick prototypes.
2 - Have clear guidelines for internal & external teams to follow
After making the current data visible across the organization, the next step is to ensure that future data is collected correctly. Having clear written guidelines will help both internal product development and any work with partners. Data guidelines must cover best processes, practices and governance models from the following departments:
IT requirements, especially on the data architecture level Legal guidelines based on GDPR and other relevant requirements Data regulations from the Data Science team within the organization
3 - Create multi-disciplinary data-driven teams for growth and give them enough support
The team is the most critical success factor in a successful organisational change towards becoming more data-driven. A multi-disciplinary team setup is the best for working fast in an uncertain environment. The team has to be able to use data, i.e., combine it with customer insights to develop hypotheses that are tested quickly. Ideally, team members should not be involved with several other projects within the organization. Expectations and definitions of success must be clear. The team must also be able to plan its activities, with additional support. If the team has a dual role as a change agent, C-suite support may be needed. Finally, careful consideration must be given to team culture and personalities when picking the members.
RUNNING THE SHOW (TEAM LEVEL)
4 - Create a hypothesis
The team defines its process based on its objectives. I have been involved in Hypothesis-Test-Result processes. Hypotheses are created based on data, customer insights, and market situation - or sometimes gut feeling. The important part is that the hypothesis can be sliced into measurable tests. The hypothesis can deal with the strategic or product feature level.
5 - Design & run tests
The primary purpose of doing tests is to find traction. Tests can be done using a clickable prototype, deployed on real product, or smoke tests that simulate ideas. Each test must be created and planned well, with carefully defined and measured success and failure criteria.
This part can get a little fuzzy and abstract sometimes, so it’s essential to ensure team morale remains high. Ideally, the process should be done in 2 weeks sprints. This phase’s processing should be rather straightforward, and results should be used for adjusting future experiments.
Example 1: Increase ARPU for existing customers The team checks the data from various sources - own data, open data, and purchased data - and creates hypotheses. For example, if a customer lives in a neighborhood that has voted for the Green Party, orders email bills, this could give insights for customizing sales & marketing efforts. After the hypothesis is accepted, then data must be modeled to estimate business impact. If the calculated business impact is good, then execution starts.
Example 2: Test the value proposition of a new SaaS service. A smoke test is designed so that during the welcoming call of the new customers, salespeople pitched the new service as if it exists and asked would customers be interested in paying for it. If customers said yes, the salesperson records the information for later contact. It’s an effortless way to gauge the initial traction. Results are more reliable than typical validation sessions with a prototype since it is presented as a real product to real customers.
6 - Analyze results & iterate
Test results must be mapped against KPI`s and carefully documented. The team looks at the results and updates the hypotheses - which would mean pivoting, or keeping the functions.
As designers we are continually adapting new ways of working, and there is no one-fits-all process but rather adaptations of many. In order to be resilient, we need to adapt our own skills to fit into the new era. We need to be able to use both qualitative and quantitative data points better in our design work. If you have any comments, don’t hesitate to contact me.
For more information about our thinking and work on data, check out our Data & AI page.
Want to learn more? Watch our Design thinking meets data – current state, future and challenges talk here.
 Korhan BuyukdemirciPrincipal Consultant, Strategic Design
Korhan BuyukdemirciPrincipal Consultant, Strategic Design

