As an Agile trainer, I sometimes get very good questions from my past students. And as I try to reply meaningfully, I sometimes end up writing something worth sharing. Here's one very recent conversation.
The question:
I am working on an agile project and I don't know when to incorporate prototyping. The project is a private web application with a number of complex workflows. We have developed high level user stories, but we would like to validate some of the user stories by testing them with a clickable prototype. I can approach this a few ways, and I am a little confused. Maybe your advice could help me. Option 1: I treat the prototype as part of the user story, as part of the iterative process. I build it into the sprint process and validate it during one of my sprints and iterate from there. Option 2: I conduct the prototype work separately before I incorporate it into a sprint and make it part of the discovery / validation process at the beginning of the project. This is how we handled the prototyping for the example I shared. The design/ux team developed and validated the prototype prior to putting the user story into the sprint. Option 3: A better solution from Petri? :)
To me, both approaches mentioned are valid approaches (what is an invalid approach? One that never works? Anyway...).
I would use option 1 in these two scenarios:
- The amount of uncertainty is manageable by the team without undue disturbance to other agreed items.
- All, or most, of team's work is stories like this. Thus, it is just the natural form of stories for the type or stage of the process, probably an early explorative stage of the product development.
- There is great haste to moving the item forward, and it is better to commit to uncertain work (and face the consequences) than to spend time learning first.
I would use option 2 when either:
- There is significant uncertainty about the thing to be done, and the team would not feel comfortable committing to the work as a Sprint story.
- There are some constraints, like an approval from third party, and that stakeholder is not reliably available for normal sprint work. For example, the appearance has to be approved by Marketing.
Many product programs end up using "two teams" - the development team and the research "team" - that share some of the members. Imagine this as two overlapping circles (which are inside a larger circle - the product). One is focused on developing well-understood stories into Sprint releases, the other is trying to understand what is worth doing. in Scrum terms, the former would be the Development Team, and the latter would be like a Product Owner office (consisting of the PO, some external stakeholders, and some of the team members on a part-time basis).
Both "teams" would have their own flows. The Development Team probably uses something like Scrum, with agreed batches (but they could also use Kanban-like flow), given that the work this team undertakes is probably well understood. The research team is likely to use a Kanban-like flow, given that the work is highly uncertain and there probably are more "balls in the air" at any given time (i.e. there is research work going on in many epics/stories at a given time, and it is not necessarily very clear how long each item will take).
Most Development Team members spend 5-10% of their time in the research team, but some members, like UX designers or domain experts, may spend as much as 50% of their time there. This depends on a given Sprint and will fluctuate as needed. The people must manage their participation in both flows in a responsible way :).
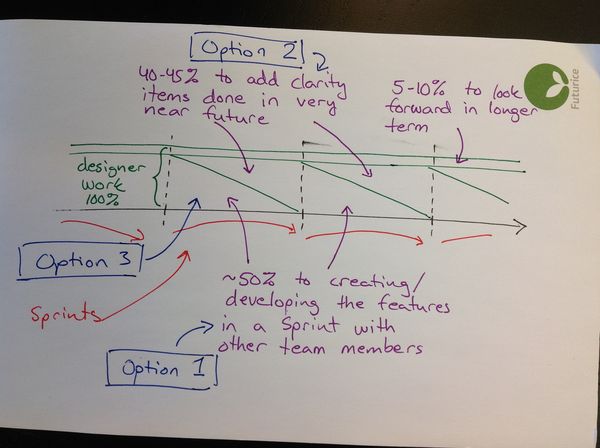 The designer's typical distribution of work and how the different options align to it.
The designer's typical distribution of work and how the different options align to it.
And there is an option 3. It's not better, just a slightly different approach.
This approach is called "spikes", "research stories", or a few other names. It's kinda like a combination of the two above. Take a research item, write it as a story, and put it into a Sprint. The outcome is a learning outcome, not a product increment. The trick is, these items are not estimated, but timeboxed. In the Sprint Planning, the Team and the PO agree how much time is spent on that item, max (i.e. less time can be spent if a solution is found in that time). When the timebox expires, the team ceases working on that item and reports whatever they learnt in that time in the Sprint Review.
I would use this approach when:
- The research items are reasonably few in number (like 0-2 per Sprint)
- There is no "PO office" to handle research
- Or if there is, but the item is heavily related to the "How", i.e. technical domain)
- The PO or the Team want to learn first (in a low-cost way) either about the What or the How, before being able to refine the story further and commit to actual development work.
- The work can be time-boxed and easily fits inside a Sprint (i.e. there is more development work than spikes in a Sprint).
Getting Agile puts useful additional detail on this option.
Depending on circumstances, I might use all three approaches in a single project, as appropriate. Each has benefits that some stories would benefit from.
 Petri HeiramoOrganisational ScrumMaster
Petri HeiramoOrganisational ScrumMaster

