How to identify problems machine learning and artificial intelligence can solve?
This article is a written companion to a talk of the same title I've given in a few different tech meetups.
The slides for that talk can be found on Github and Slideshare.
Artificial intelligence, machine learning, neural networks, deep learning... If you follow technology news, chances are you've seen these terms. There's a lot of hype around machine learning these days, and it's hard to know how it applies to your own business or project. Here, I'll cut through some of that hype, identify some real use cases, and give some pointers for how to identify problems that machine learning can solve.
Artificial intelligence (AI) is not a very useful term in this discussion. It's a powerful, evocative phrase, conjuring up images of HAL from 2001, Skynet from The Terminator, or maybe GLaDOS from Portal, depending on your pop culture tastes. Science fiction often portrays AI as a system that thinks, reasons, and learns in a human-like way, but, frankly, that's pretty far from where we are.
When you read a headline like "AI learns to do task X", it actually means that a researcher or data scientist wrote a mathematical description of the task, collected a bunch of example data, and used techniques from machine learning to learn a set of rules from that data. It's a laborious process that requires a lot of human oversight. Allison Parrish put it pretty well:
Embedded content: https://twitter.com/aparrish/status/713703634635268096
This kind of "AI" has a narrow focus on answering a single question, and can't generalise to function in totally new contexts as a human can. If I show a chess board to my self-driving car, it's not going to learn how to play.
However, all this is not to say that these efforts are useless. Within their own narrow areas of focus, machine learning systems can often achieve super-human performance. Amazing things can be achieved by choosing the right questions to answer.
What is Machine Learning?
Machine learning is the study of algorithms that learn from data. Rather than explicitly writing a series of steps to solve a problem, as in traditional programming, you input a description of the goal and a large number of past examples. The system then uses mathematical and statistical techniques to learn to accomplish the goal as well as it can. In some sense, it's like having the computer "program itself".
Machine learning is a toolbox of techniques that let us learn from examples. Deep learning is one of the tools in that toolbox and has been successfully used in many different areas in recent years. Deep learning is based on the artificial neural network, a technique that's been around since the 1950s. Recent advances in both computational power and the training process for these networks have allowed deep learning to flourish.
The most common type of machine learning is what's known as supervised learning. This covers tasks of the form "given a situation A, predict an outcome B". Each piece of data is a historical situation, labelled by its outcome. Based on these examples, the machine learner tries to learn to predict the outcome for new, unseen situations. The trick to creating a useful system lies in choosing the right A and B.
Self-driving cars are a good example. One of the many problems they have to solve is how to adjust the steering to stay on the road. The simplest way to do this is to take a picture of the road in front of the car, and predict the correct steering direction from that. Our situation (A) is an image from a camera, and our outcome (B) is a steering wheel angle.
Carnegie Mellon University created a neural network based system called RALPH that handled the steering wheel of a minivan as it drove nearly 3000 miles from Pittsburgh to San Diego. RALPH remained in control 98% of the time on this cross-country drive. The human operating the pedals had to take over the wheel for trickier intersections. The coolest part? CMU did this in 1995. The technology has been around a long time, but is only now becoming mainstream.
 Navlab 5, as driven by RALPH.
Navlab 5, as driven by RALPH.
What is machine learning good for?
The obvious next question is: when should we use machine learning? What kind of problems is machine learning good at solving? Andrew Ng, a professor at Stanford University and prominent machine learning expert, has a pretty far-ranging answer for this. Writing in Harvard Business Review, he said:
"If a typical person can do a mental task with less than one second of thought, we can probably automate it using AI either now or in the near future"
That's a bold statement, and I'd argue there are plenty of things humans can do in less than a second of thought that are not good candidates for machine learning. As a simple counterexample, think about the problem of parity: determining whether a given number is odd or even. I hope you'll agree most people can do this in less than a second. Plus, it's trivial to collect labelled examples - 322 is even, 343 is odd, 42 is even, and so on - that could be used to train a machine learning system.
The problem is that given data like this, many popular machine learning algorithms will completely fail at predicting the parity of an unseen number - they'll be no better than random guessing. This problem can be overcome by giving the algorithms more inputs to work with, but this requires problem-specific knowledge. The point is, there are problems where a blind application of machine learning will yield nothing.
Here's an alternative rule of thumb. You might have a machine learning problem if:
- It's difficult or impossible to write down a set of rules, but
- It's easy to collect historical examples
The parity problem fails on the first point. The rules are very simple: even if the number is divisible by 2, odd otherwise. There's no need to use machine learning when the solution can be simply expressed as a regular program.
An example of a problem more suited to machine learning: "is there a cat in this image?"
 Is this a cat?
Is this a cat?
This passes the Ng criteria: it takes less than a second to judge an image. It also meets our two additional conditions. It's very hard to write down a set of rules that takes an arbitrary image and determines the presence or absence of a cat. However, luckily for us, the internet is an elaborate machine designed to produce cat pictures, so it's easy to get example data.
Object recognition in images is a classic machine learning problem. Various techniques, especially those based on neural networks or deep learning, have had great success at solving it. Being able to accurately recognise cats is technically impressive, but not necessarily very useful from a business point of view. This was parodied in the show Silicon Valley with the app Not Hotdog (a real app they actually implemented). That gives us another important rule: before using machine learning, make sure the outcome you're predicting is actionable and creates value for your business.
Use Cases for machine learning
Having rules for when to apply machine learning is good, but it's also useful to see how other people have already successfully applied these techniques. There's a huge number of machine learning algorithms, but many popular applications fall under three main categories.
Predicting the future
The task of supervised learning described above is perhaps the most common application of machine learning. Essentially, the goal here is to predict the best future actions given the available historical information. Such predictions can be further broken down into two classes, depending on the type of quantity to be predicted.
The first class is regression, where the goal is to predict a number.
Demand forecasting for supermarkets is one example: given a product, how much should I order for my next stock delivery? Store owners want to make sure there's enough product on the shelves to satisfy demand, while avoiding overstock taking up expensive space in warehouses. It's especially important not to order too much of perishable goods that will have to be thrown out if not sold in time. Machine learning models to make these predictions take into account past sales, similarity between products, demographics of each store's customers, and many other factors.
The stock market is another example: what's the optimal price to buy or sell a given share? Human traders are increasingly supported - or even replaced - by algorithmic systems that re-estimate prices and make transactions hundreds of times per second. Such systems buying and selling from each other account for an unnerving share of the world economy. Their pricing models bring in historical trends, real-time transaction data, tips from human advisors, and even sentiment analysis scraped from social media.
The other class of problem is classification, where the prediction is one of a finite set of options.
This might be a binary yes/no choice, or a selection from a bigger set of options, depending on the exact application. Think about face recognition: Snapchat might be interested in whether or not a face is in an image, so they can decide to apply filters; while Facebook might be more interested in whose specific face is in the image, so they can make tag suggestions. Futurice have employed face recognition at Helsinki Airport as a prototype for a hands-in-pocket travel experience.
Classification is also important in the medical domain. Image recognition techniques can process thousands of past scan results to learn the characteristic patterns of many diseases, resulting in diagnostic accuracy that is approaching and in some cases exceeding that of human doctors. Other algorithms can blend diverse data about symptoms, test results, and live vital readings to make accurate diagnoses. In bio-medical research, huge datasets on gene expressions and chemical signatures allow new links between diseases, genetics, and treatments to be discovered.
Recommending content
The second major category of machine learning application is content recommendation. Lots of businesses have content of some kind. This might be traditional media - written articles, videos, and so on - or products sold in a store. Google's main content and source of revenue is ads. Whatever the format of the content, not all items will appeal to all people equally, so companies have a vested interest in personalising the content shown to each user. As a machine learning task, this amounts to predicting how much a given person will like each piece of content, so that recommendations can be made.
One major strategy is content-based recommendation, which is exactly what it sounds like: suggesting items similar to content a user has already liked. This can be as simple as recommending articles by the same authors or videos from the same channels users have looked at before. Alternatively, it could involve analysis of the text in an article to extract the main topics, then recommending other articles on the same topics.
There are a couple of problems with this approach. First, it's not always easy, or even possible, to define similarity between items. This is especially true for companies with diverse offerings, like Amazon. How similar is a vacuum cleaner to the latest PS4 game? Secondly, there's the problem of what to recommend for new customers who haven't consumed any content yet. We don't know their tastes, so we can't recommend similar items.
These problems motivate a second approach, called collaborative filtering. The idea here is to recommend items other users have liked. When a user is new, you can just recommend the most popular items across all users. As they consume content, you can personalise the recommendations based on the habits of similar users.
This is how Spotify's Discover Weekly works: first, your listening history and created playlists are analysed to create a profile. Then, Spotify finds other users who have similar habits to you, and creates a playlist from songs that those users have listened to, but you haven't heard yet.
Netflix is another well-known user of collaborative filtering. Giving customers a steady stream of fresh content tailored to their tastes is an important part of keeping them as subscribers. Famously, in 2007 they announced the Netflix Prize, a competition offering $1,000,000 to anyone who created a recommendation algorithm that was at least 10% more accurate than Netflix's own. Teams of researchers competed for 2 years before one group broke the 10% barrier and won the money. Interestingly, Netflix never used the winning solution in production, partly because of engineering restrictions and partly due to a business model shift from DVD mail order to streaming.
Uncovering hidden structure
The last big category of use cases is a bit different. In regression, classification, and recommendation, we were trying to predict some output for a given situation. What if we don't have something specific to predict? What if we just have lots of data about past situations, and want to know what's interesting about it?
This is the problem of unsupervised learning. This is a much harder problem than the others, because there's no "truth" to compare against. The results are generally subject to human interpretation.
Unsupervised approaches allow you to answer different kinds of questions, like: What kind of groups exist in the data? Is some part of the data unusual compared to the rest? What are the recurring patterns in the data? The answers to such questions can be useful on their own, or they can be used as a preprocessing step before applying supervised learning techniques.
User segmentation is one of the most common applications of unsupervised methods. Consider a company who operate a mobile game, and maintain an extensive log of the actions players take in the game. By analysing these logs, the company can identify groups who act similarly. Maybe one group logs in regularly, and spends money on the in-game store. Another logs in every other week, and plays for a few minutes without spending money. These groups can form the basis for further analysis: the company might look for the kind of levels the first group plays the most, so they can create similar content and keep them engaged; or they might target offers to increase the playtime of the second group and convert them to paying customers.
Financial institutions make heavy use of unsupervised techniques to combat fraud. When processing credit card transactions, they are on the lookout for purchases that don't seem to fit established patterns. It can be hard to get good data on which transactions are truly fraudulent, but by considering user history, unusual items can be flagged. Systems might consider factors like time since the last transaction, number of transactions in the recent past, difference from the average transaction amount, and physical location of the vendor compared to historical purchases in order to assign a novelty score to each transaction. When the score is high, purchases might be automatically declined or flagged for manual review.
Putting things together
Some companies are starting to use supervised and unsupervised techniques together. Google News is a great example. The site aggregates stories from many media outlets, and unsupervised learning automatically groups different versions of the same story from different authors. The key topics of the top stories are also extracted automatically and shown in the sidebar. Meanwhile, classification is used to assign stories to the appropriate categories (Business, Health, World News, and so on). There's also content recommendation, as the service takes into account user preferences and offers a personalised list of articles. All this is done with minimal input from human editors.
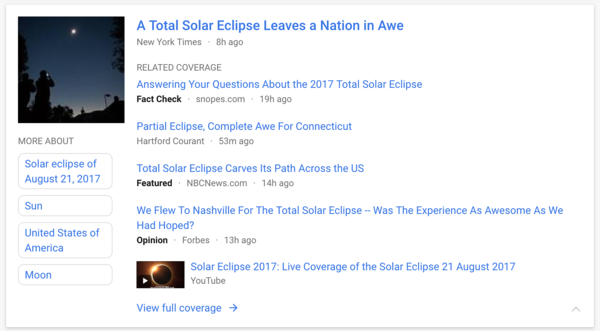 Google News automatically gathers related stories together and lists the key topics.
Google News automatically gathers related stories together and lists the key topics.
Summing thoughts on applying machine learning
Machine learning is here to stay. Businesses are turning to these tools as a way to make sense of ever-growing datasets and seek competitive advantages. Big companies like Google, Facebook, and Amazon have talked about the transformation of their engineering and business to focus on data driven approaches. Academic publications and open source libraries like Google's TensorFlow are enabling wider access to these techniques. Even the notoriously insular Apple have started allowing their employees to publish machine learning papers, just so they can compete for the pool of talented researchers.
Despite this, machine learning remains shrouded in hype and harried by fear-mongering around the perils of artificial intelligence. If you made it this far, you should have a better idea of where we really are with this technology, and how people have found success with it so far.
If you skipped to the end, here are some key points to take away:
- Machine learning systems aren't general purpose: they excel at providing answers to narrow, well-defined questions
- Look for business problems where it's impossible to write down the rules, but easy to gather examples
- Whatever you set out to predict, make sure it's actionable - if you can't change something in response to the prediction, it's useless
If you need more advice on how to apply machine learning in your own business environment, the Futurice data science team can help: get in touch!
 Daryl WeirSenior Data Scientist
Daryl WeirSenior Data Scientist




