At-least-once Delivery for Serverless Camunda Workflow Automation
In the last blog, I showed how to run Camunda business process management engine using Terraform in a serverless environment. The next job is to delegate work to external serverless microservices for implementation. The challenge is doing so *reliably*, with at-least-once delivery semantics, in an event driven manner.
Interesting, Camunda discourages the event driven push approach, and instead recommends external tasks pull from the workflow engine. Pull, however, does not follow the grain of modern event driven serverless architecture. I spent some time to figure out how to get reliable at-least-once event delivery to-and-from serverless Camunda, using managed Cloud infrastructure, and discovered a fair bit of nuance along the way. Code is public.
Why Serverless?
Deploying Camunda on a serverless container host like Fargate or Cloud Run can offer significant cost savings and operational simplicity (e.g. automatic scaling). By using external FaaS technology (Lambda, Cloud Functions) to implement supporting microservices, you can isolate security boundaries better with execution service accounts, keep secrets out of the engine and divide implementation between teams better.
It's cheaper. It's more secure. It's easier to operate.
Why Push driven?
Pull based external tasks are against the grain of FaaS's event driven architecture. Camunda recommends that external tasks periodically pull for work. But periodic pulling prevents the engine from scaling down to 0, and thus nullifies a big driver of cost savings.
Push delivery of messages allows scaling of downstream in response to workload. It enables elastic architectures which can scale horizontally and down to zero. You need a push driven architecture to host code in functions-as-a-service, which have their own long list of advantages.
However, it is tricky to get right, which is why I think Camunda suggests avoiding it. The main challenge is delivering messages reliably, i.e. at-least-once delivery mechanics. Building at-least-once message systems is hard, luckily our cloud providers have done most of the hardwork and we just have to know how to exploit them.
Building blocks
I did not want to dive into custom Java code for this project. It makes it hard for people to replicate. So I set a goal of using only out of the box functionality. Before we get to a concrete example though, we need some basic building blocks.
Generic Http Client with Sane Retry Policy
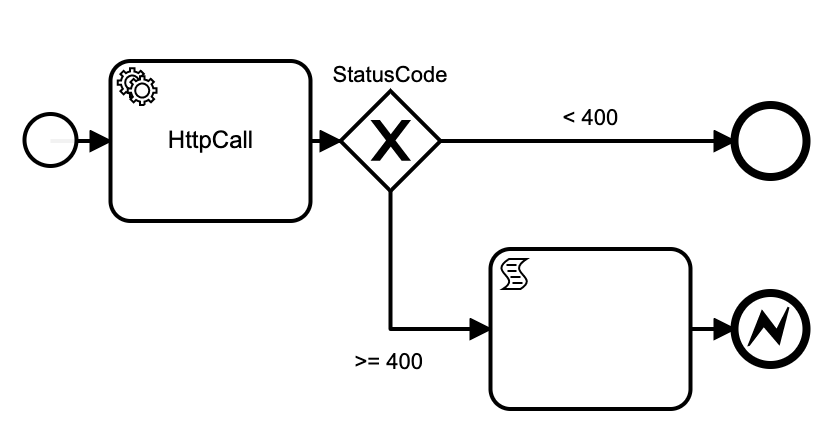
For at-least-once delivery, transient failures must be retried. We wrap the http-connector plugin with a decision based on the response code. Google cloud often throws 429's when a system is still scaling up, so you should retry those. You probably shouldn't retry 400s, but this is an MVP so I kept the diagram simple. By terminating the process with an Error, Camunda's retry logic can kick in to callers of this activity.
Inputs: url, method, headers, payload
Outputs: statusCode, headers, response
Generic Publish to Pubsub
Publishing to pubsub's REST API requires a Bearer token in the Authorization header. Cloud Run can fetch a token for its active service account via a GET to the metadata server. So publishing can be achieved with two REST calls.
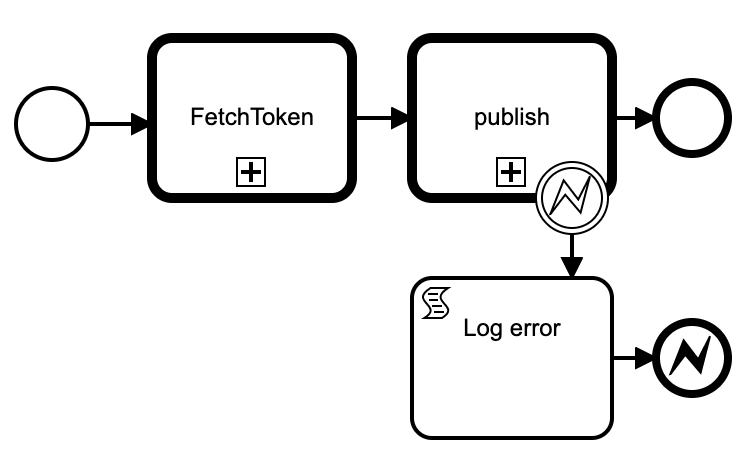
inputs: project, topic, message -- TODO: attributes
We don't really need to catch the error, but it's informative to print it out (the failure could be non-technical like a quota problem and you really want to see those)
Generic Message Receipt
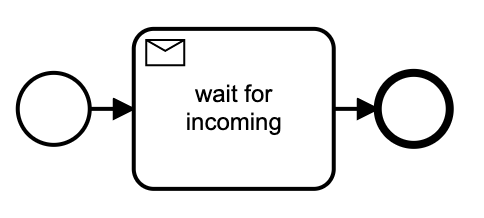
The default wait for message task allows external tasks to POST a message to the engine to kick off processing. The default implementation is enough for our needs.
Combining the Building Blocks for At-Least-Once delivery
To figure out if we can do external at-least-once delivery with response semantics, we deploy an external Echo service that responds by posting a message back to the Engine. This requires reliability in the face of outbound transient errors, and reliability in posting inbound messages back to the engine.
We use Pubsub as the outbound transport because
- Its fully managed (Yay no Kafka cluster) and handles its own storage of messages
- It's probably more reliable than a home grown service
- It connects directly to Google Cloud Functions
- It has its own at-least-once features
- It's fast, so we return control to the Camunda engine quickly. The time required to execute the external tasks becomes completely decoupled from Camunda
- We can redeploy the downstream service without affecting the message stream
We use Camunda's off-the-shelf REST API for delivering return results because
- It's there
- It deduplicates repeat messages for exactly-once processing semantics
Echo External Service
We deploy a simple echo service in Google Cloud Functions that POSTs a received pubsub message to a URL.
Embedded content: https://gist.github.com/tomlarkworthy/c0d50934b1db2e6d3ddfb719b6342db1?file=echo.tsIn our experiment we will be posting Message resources to the Camunda message URL like so
{"messageName":"echo","businessKey":null,"processInstanceId":"<ID>"}
Camunda will respond with status code 200 when it accepts a message, or 400 if it cannot route messages (this happens if the same message is delivered twice).
For at-least-once delivery we turn on automatic retry logic for this function. Note if there is a network hiccup we might not always be notified of the delivery success, in which case the function will retry and the second delivery will get a 400. So a few rare 400s are expected, and thus should NOT be retried.
Echo Task: At-least-once Push Delivery Sample
With the function deployed, we can now trigger it by publishing to its topic, and we can listen for its results by setting up a Message receive task.
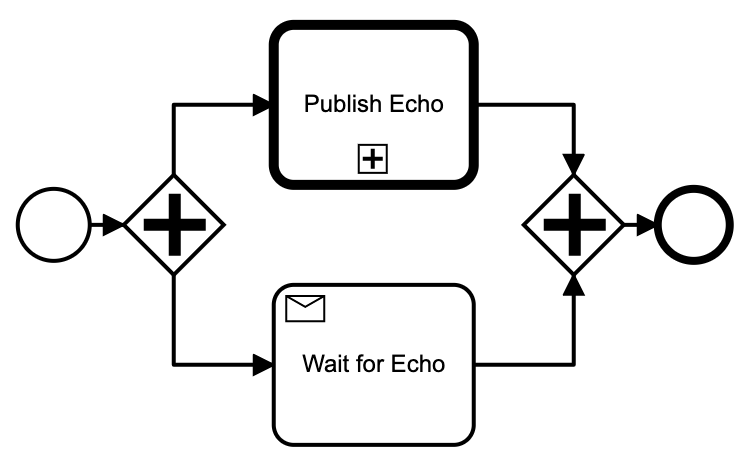
While the diagram is notionally simple, there is a fair bit of engineering details hidden in configuration
- Failed publish tasks should be retried forever
- Set "failedJobRetryTimeCycle" to "R999999/PT30S" (seems like a bug that R/PT30S retries only three times)
- Sometimes the echo service runs so fast the return message is posted before the receive task is active, which leads to a 400 and is not retried
- Set an non-exclusive async-before continuation on the publish, so the wait task and the continuation are setup in one transaction preceding the publishing.
- Often we get an optimistic lock exception at the join causing the publish to be retried pointlessly
- Set an async-after continuation after the publish, so we never retry a successful publish.
I had a few implementation gotchas I hit when developing
- Async jobs did not start because the intermediate data was not serializable
- Nashorn engine was diabolically slow on JRE 11 (3 seconds minimum per script, 10 seconds for a script that base64 encoded a short string), so I switched to Groovy
Testing: Is It Really at-least-once delivery?
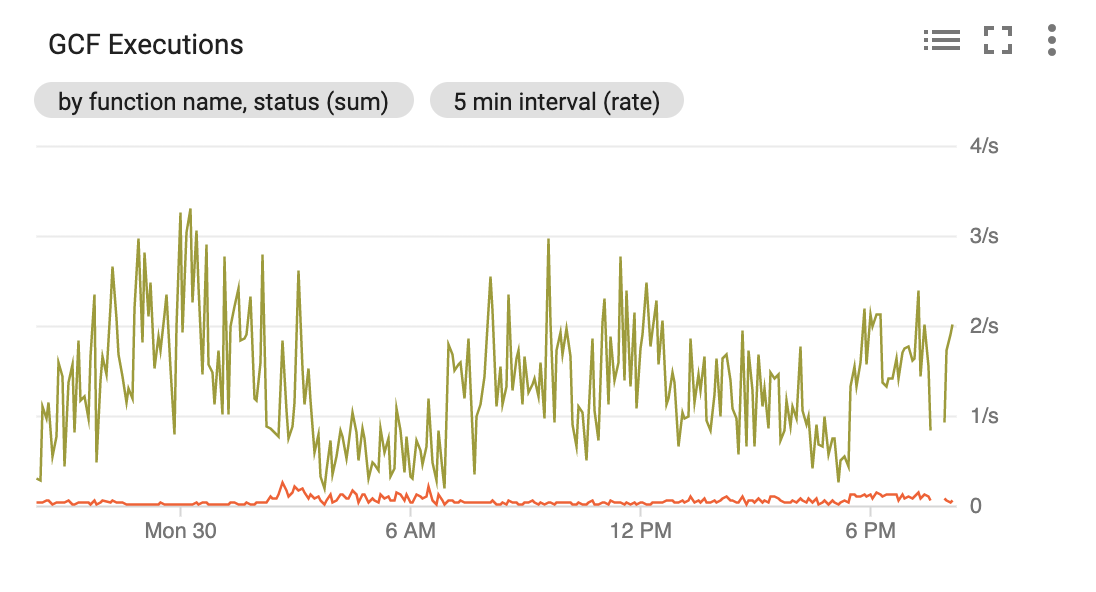
To test reliability I connected the Echo task in a loop. Once started, it should just keep retriggering itself. We want to check that the causal chain of self-triggering is never broken, even in the face of transient errors. Another common failure mode is the processes start multiplying, when we want exactly-once processing semantics.
BTW this loop test was how we tested Firestore and Realtime Database integrations with Google Cloud Functions. It's a brutally sensitive test when run for months (especially though platform outages!).
This loop survives reploying both the Echo and Camunda services! Here are the graphs of it running overnight, and you can see patches of errors at various locations that it survives.
We even captured the cloud run service being scaled to zero and waking up and carrying on:
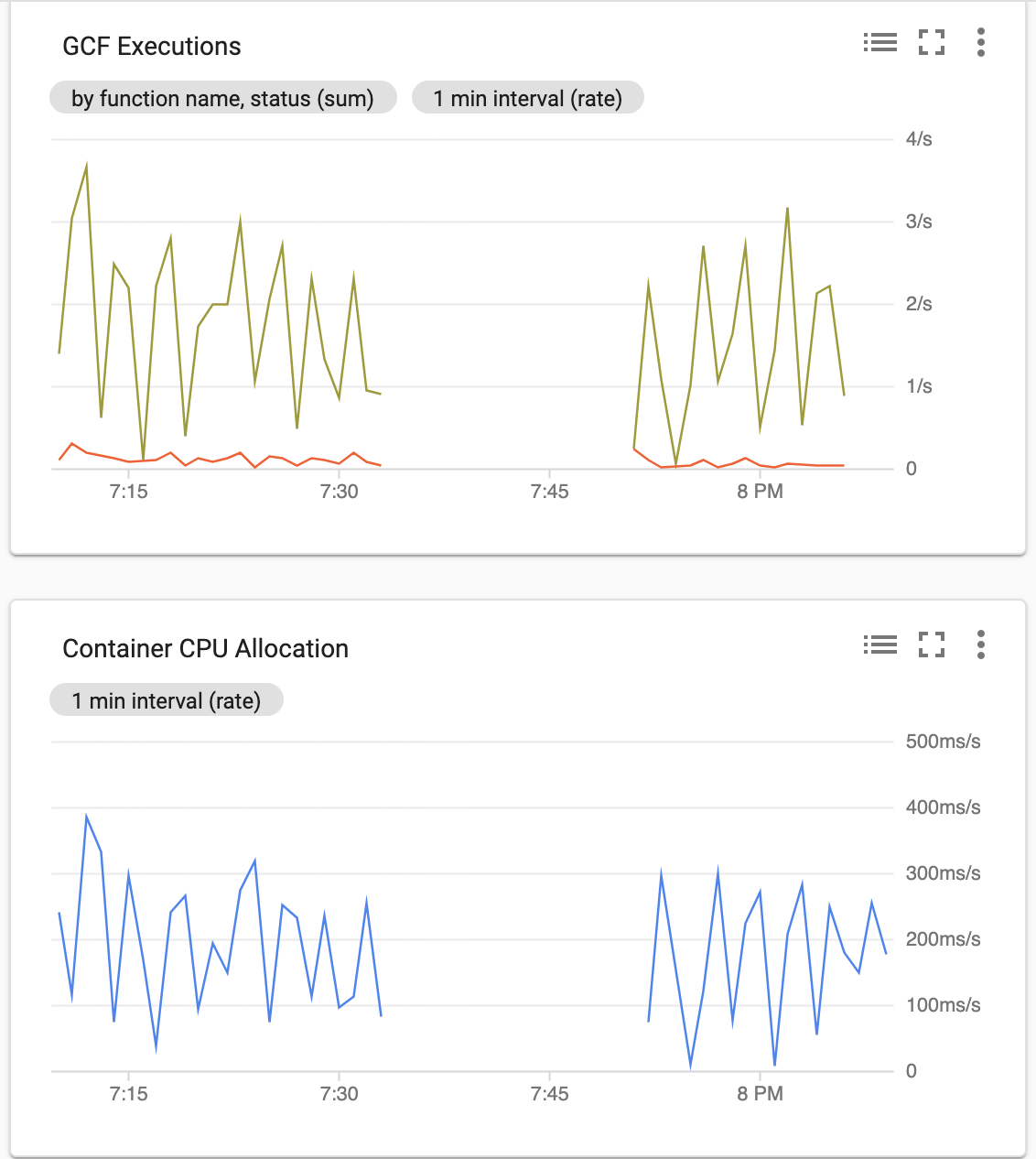
Round trip latency was around 500ms, despite our woefully under provisioned shared f1-micro Cloud SQL database instance.
Futurice ♥ Open Source
We added the ability to configure the bpm-platform.xml in our futurice/terraform-examples repository mentioning the previous "Serverless Camunda Terraform Recipe" blog. All the code in this blog is availible here.
Unlocking Serverless Camunda
This experiment demonstrates we can run external tasks, and collect their responses reliably using PUSH delivery semantics. This is bidirectional information flow, orchestrated by the engine. We achieve this using out-of-the-box functionality -- I never even had to write a retry loop! This communication pattern fits serverless computation perfectly, and allows the downstream tasks to scale to demand automatically. Furthermore, the engine itself scales horizontally too.
This pattern will allow external services to be written in whatever language makes sense, and run in their own service account for minimum privileges, and scaled independently to the process engine. We have decoupled task execution and implementation from task scheduling and workflow design.
Now I can start building generic application microservices weaved together using custom business processes! Let the true fun begin.
 Tom LarkworthySenior Cloud Architect
Tom LarkworthySenior Cloud Architect


