
Foreword by Teemu Turunen, Corporate Hippie of Futurice
In 2017 Futurice does digital charity projects with a budget of half a million euros as an extension to our open source and social impact program. The investment is mainly made as work by our employees. In January we asked for project applications. One of them, suggested to us by a group of respected researchers active in the Citizen Mindscapes collective, can be summarised as:
People often discuss prescription drugs online. How closely they follow the doctor's instructions, what they think about the drugs, what kind of advice they give to each other… how they relate to the medicine, when the doctor is not present. A large database of Finnish forum discussions exists and can be used for data analysis to refine valuable information regarding this subject to be shared with researchers, doctors, and other relevant parties.
Our employees considered this open data science project both interesting and important. We decided to go ahead with it.
The original concept changed quite a bit during the summer. Originally we wanted to do sentiment analysis; to determine the attitude of the writer by automatically extracting sentiment from the forum discussions. This unfortunately turned out to be too difficult, as sentiment labeled datasets are not yet available in our archaic language. Our data scientists tried different approaches through the summer, working full time on the project. What kind of valuable connections can we find in the forum data provided for the project by Aller? How should we present these findings?
These different approaches and findings were presented to the Citizen Mindscape researchers, and as a result of an iterative process the Lääketutka service, also known as the Medicine Radar, was created. We hope you find it valuable.
Motivation
A man walks into the doctor’s office. He has a heavy flu and a high fever. The doctor prescribes him antibiotics and some painkillers, and sends him home. What happens next? Does the man understand that he has to take the entire prescribed regimen of antibiotics, or does he simply stop taking them after a few days – after all, he "feels better already”. Maybe he even stashes the rest of them so that next time, when he has another fever, he can simply use his stash. No need to see a doctor.
To say that this kind of behavior happens would be a massive understatement. But can a doctor even know when their patients take their medicine? Do the people running clinical trials on new, possibly dangerous drugs, know how their patients actually use the medication given to them? To be able to tell what goes on in the head of someone you’d have to ask them, and let’s be honest: if a doctor asks a patient “Did you take your medicine as I told you?”, we all know what the answer is going to be, regardless of what actually happened.
Does the man understand that he has to take the entire prescribed regimen of antibiotics, or does he simply stop taking them after a few days – after all, he "feels better already”.
When doctors and health specialists prescribe medicine, the assumption is that the patient takes the medicine in the way that the doctor told him, e.g three times a day for seven weeks. Even if they complain that the drug didn’t help them, they might leave out important aspects of the why, simply because they don’t want to be shamed for disobeying orders.
But guess what? Everybody needs to talk about these things, and in the 2000s, what better place to talk about it than an anonymous internet forum. Luckily, we have 16 years worth of anonymous discussion data from Finnish internet forum Suomi24 and Aller (owner of Suomi24) has graciously offered their data for research. Stories like the one just told are plenty there. What could we learn from these stories? Could they help in understanding and better informing patients? The goal of this study was to gain a deeper understanding of what actually happens after the visit to the doctors – the whole journey, if you will.
Down the rabbit hole
We had many research questions and one of the first we tackled was: which drugs are most discussed about? To answer this, the first step is being able to detect when people are talking about a specific drug. Surprisingly, this is not trivial, as the Finnish language lets one talk about the same thing in a variety of inflected forms. To give an example, one might say “tykkään vetää burnaa” or “buranasta tuli paha olo”. In both cases, the writer is referring to the drug “burana”, but the word is different. We use a variety of ad-hoc tricks, heuristic rules and lemmatization to group together inflected forms of the same word.
Furthermore, we needed a list of drugs to recognize which words refer to drugs at all. We did use lists of drugs found online, but they were far from exhaustive. Also, people invent new slang terms for drugs with difficult names, and typo them all the time. Therefore, we wanted to produce our drug list directly from the discussion data. However, it’s not practical to go about reading posts and picking out any words that one might see.
Here’s where the fancy new machine learning stuff comes in. Using a neural network, we can train a model that represents each different word in the entire data as a vector. Think of a vector as an arrow in the plot: it has a direction and a length, and vectors are similar when they are near each other.
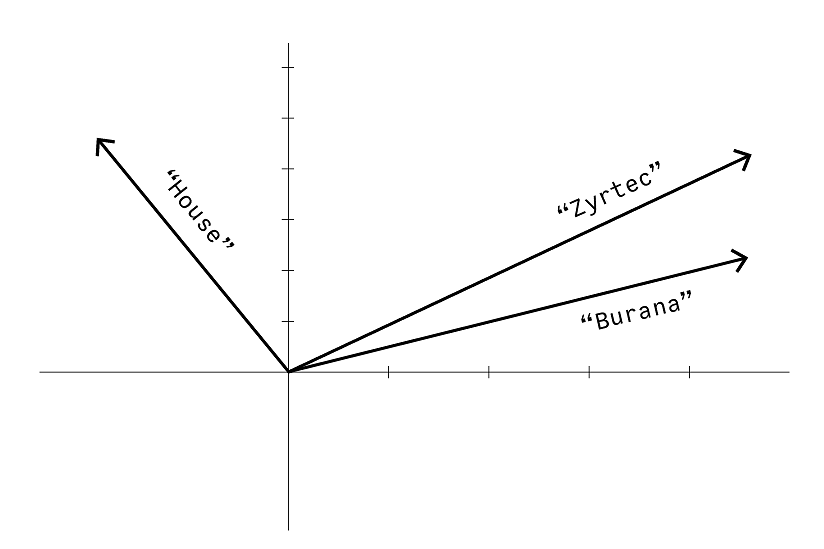 Similar words have similar vector representations
Similar words have similar vector representations
The goal for the neural network is to assign each word a vector in such a way that words with similar properties get a similar vector. The image relays the thought: Zyrtec and Burana are both medicines, so they get vectors close to each other. On the other hand, words that don't have much to do with each other get vectors that aren't very similar, such as those for House and Zyrtec. Obviously, we can't represent many words and the relationships between them by drawing them on a two-dimensional image like this. However, the actual vectors have hundreds of dimensions, which allow them to represent even complex relationships between words. You can read more about the general family of algorithms here.
So how can a neural network possibly learn the relationship between Zyrtec and Burana? The answer lies in context. Consider the following sentences as an example:
I used burana to treat my fever
Someone used zyrtec to treat his allergy
The words burana and zyrtec had a similar context in these sentences: they were both used to treat something. Since this is a common theme on Suomi24, the neural network should assign similar vectors to these words. Using this knowledge, we came up with a semi-automated tool to reliably collect lists of drugs – or any related words really. One inputs a starting word, and the tool starts suggesting words with similar vectors. The user can then accept a word or reject it. Accepted words are also used as new “seeds” for further searches.
With this tool we collected a list of over 1300 different drug words, which include slang words that could never be found using premade lists given by drug companies or health authorities. With the ability to group together different inflected forms of the same word, we could expand these 1300 initial words into tens of thousands with no manual work. Now we could finally see which drugs are most discussed about. Since each word in the chart is actually a collection of all the different words we think refer to the same thing, we pick the most common word to represent the collection. That’s why, for example, bentsodiatsepiinit is listed as bentsoja.
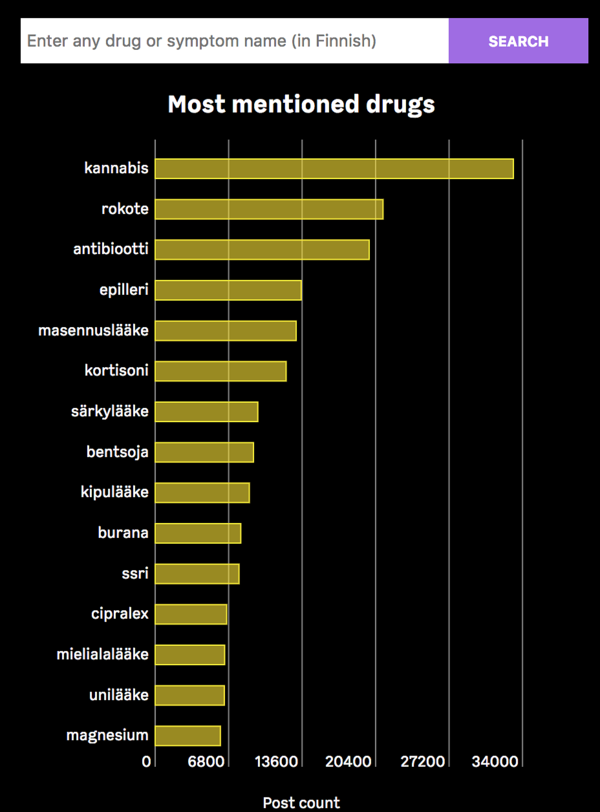 Screenshot from Lääketutka
Screenshot from Lääketutka
As we moved onto other research questions and created tools to solve them, we realized we could provide many of these tools as a real-time, open web service. We call it Lääketutka, or the Medicine Radar. It allows anyone to discover connections between drugs, symptoms and dosages – as they appear in the discussion data. We believe this service will be a valuable tool for qualitative research into social media. It can also provide doctors and medical students a more complete view of patient mindscapes.
Written by Chang Rajani and Atte Juvonen
 Atte JuvonenSoftware Developer, Data Scientist
Atte JuvonenSoftware Developer, Data Scientist


