Case study: How to test a service under production load before going to production
Have you ever run into production problems that you wished you could have caught earlier? This post looks at utilizing shadow traffic and canary traffic in Nodejs and TypeScript to test your service under production load before going to production. There is an attached working code repository for anyone to follow along with, or even to clone and test the functionality yourself: https://github.com/futurice/shadow-and-canary-traffic-example

As a software developer working on Nodejs and TypeScript I’m used to having very short feedback loops. The editor highlights static mistakes as soon as I make them (think trying to access a property that doesn’t exist for a given type), the applications usually runs in some sort of watch mode and crashes instantly if I introduce a runtime error, the tests can be running in watch mode, and so on. Very long feedback loops seem to go against the very idea of Agile.
With this in mind, I’m terrified of the idea of building a production critical system and taking it to production without being able to know it will work as expected. I’m not against testing in production by any means, but some applications are such that the initial go-live is bound to be a big waterfall-esque change.
This post looks at practical ways of avoiding this fear, when operating in the popular Nodejs application environment and TypeScript programming language.
Case: Building New Data API to replace Old Data API
I was recently working on such a project for a client. We were building a New Data API to replace an Old Data API in a larger distributed system. The data API incoming request volumes are in the ballpark of 10,000 to 20,000 requests per day, so by no means web scale. On the other hand, if the API fails to deliver data, it has a huge impact on the user experience, as the end client application’s main task is displaying this data. So the idea of hot swapping the API and only then seeing if it works properly sounds, again, terrifying.
Note that all kinds of load creation tools such as Artillery do exist and are useful for testing a service under heavy artificial load. However, actual production load tends to be unpredictable, if not in terms of number of requests, at least in terms of variety of requests. Automated load testing helps you find out the performance limits of your application, but not necessarily the edge cases that may occur. Another aspect is time, a momentary load test might not expose issues that occur over time under load, such as database performance suffering under expensive queries, memory leaks materializing, blocking operations or such.
How to not be terrified of going live?
In the context of this post there are two things I want to look at:
- Exposing the service to production traffic before production depends on it. This is often called traffic shadowing.
- Gradually exposing the service to traffic. Canary deployments address this issue.
Both of those strategies are usually implemented on the infrastructure level, but we decided to operate on the Nodejs application level instead. Why? Several reasons, actually:
- The infrastructure level strategies usually rely on load balancing between the client (in our case the Nodejs microservice) and the target APIs, and in our case we didn’t have load balancing in place between those.
- Old Data API and New Data API have different API implementations, old being XML/SOAP and new JSON/REST. Therefore operating purely on network level wouldn’t have suited our needs anyway, as the integration clients need to be written separately for both.
- The migration from Old Data API to New Data API is a one time thing, and similar capabilities should not be needed after that. This is why adding load balancing on the infrastructure level didn’t seem to make sense.
- Making iterative changes on the application level tends to be much more flexible than on the infrastructure level, especially in the case of a one-off type of change and in our architecture.
- We had application level logging and metrics already in place, so that we were able to leverage those directly in the performance testing, as we will see below.
There’s a working reference repository on GitHub that you can follow along with, or even run the application yourself and do any kinds of testing you wish. Note that the actual data APIs aren't about animals, but this will do for demonstrating the concept. https://github.com/futurice/shadow-and-canary-traffic-example
The application architecture
A web client application makes a request to a microservice, which then makes a request to the data API (among other services) to fulfill the request. The microservice is written in TypeScript and runs on Nodejs in a Docker container, orchestrated by AWS ECS. The simplified infrastructure architecture looks like the picture below. In reality there is an API Gateway and authorization layer between the web client and the microservice, but that’s outside the scope of this functionality.

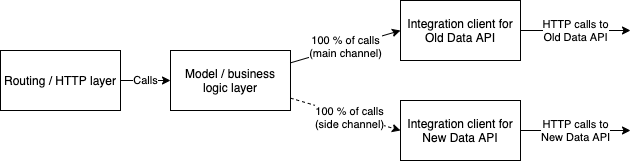
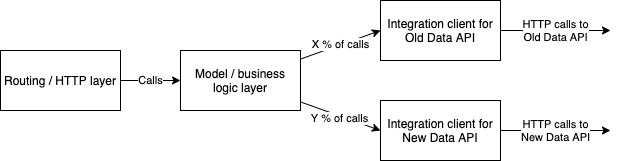
If we zoom inside the microservice itself we can see that its architecture mirrors the infrastructure architecture, just on a smaller scale. The request comes in on the HTTP layer, gets directed to the business logic layer (model), and the model then calls the appropriate integration client for whichever backend API the request needs.

The process needed for taking the New Data API in use requires writing a new integration client for it, and calling that. Ultimately it comes down to replacing a function call in the model with another function call. Currently it looks as simple as:

With this in mind, the model possesses a lot of power, and can be used for agile iterations in how traffic is routed to the data API(s), without having to modify the infrastructure layer. The connection from the microservice to both data APIs is direct, in that there is no load balancer in between, which could otherwise be used for traffic (re)direction changes. Even if there was, operating on application level can offer faster iterations, but this of course depends on the bigger picture case by case.
Example: Traffic shadowing
The idea of traffic shadowing is to duplicate all the incoming requests to both Old Data API (main channel) and New Data API (side channel). The client gets all its requests served by Old Data API, the side channel is something that the client doesn’t know or care about. However, both the microservice and New Data API can log and monitor the side channel requests as you please.
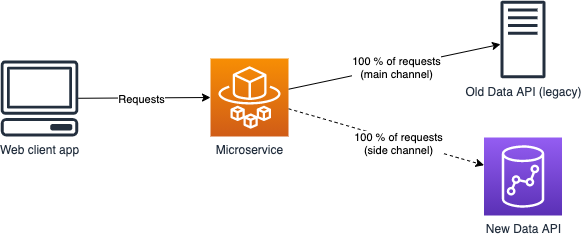
On application level the idea looks as follows. The model effectively calls both New Data API client and Old Data API client, but only returns Old Data API client to the HTTP layer, and onward to the web application client.
Note that no external references to the side channel request are stored, so no memory leaks take place. However, during the request processing the requests are effectively doubled. If you are running at near maximum capacity memory usage, and the request payloads are large, you might need to consider the temporary memory usage implications this might have. On code level it looks like this:
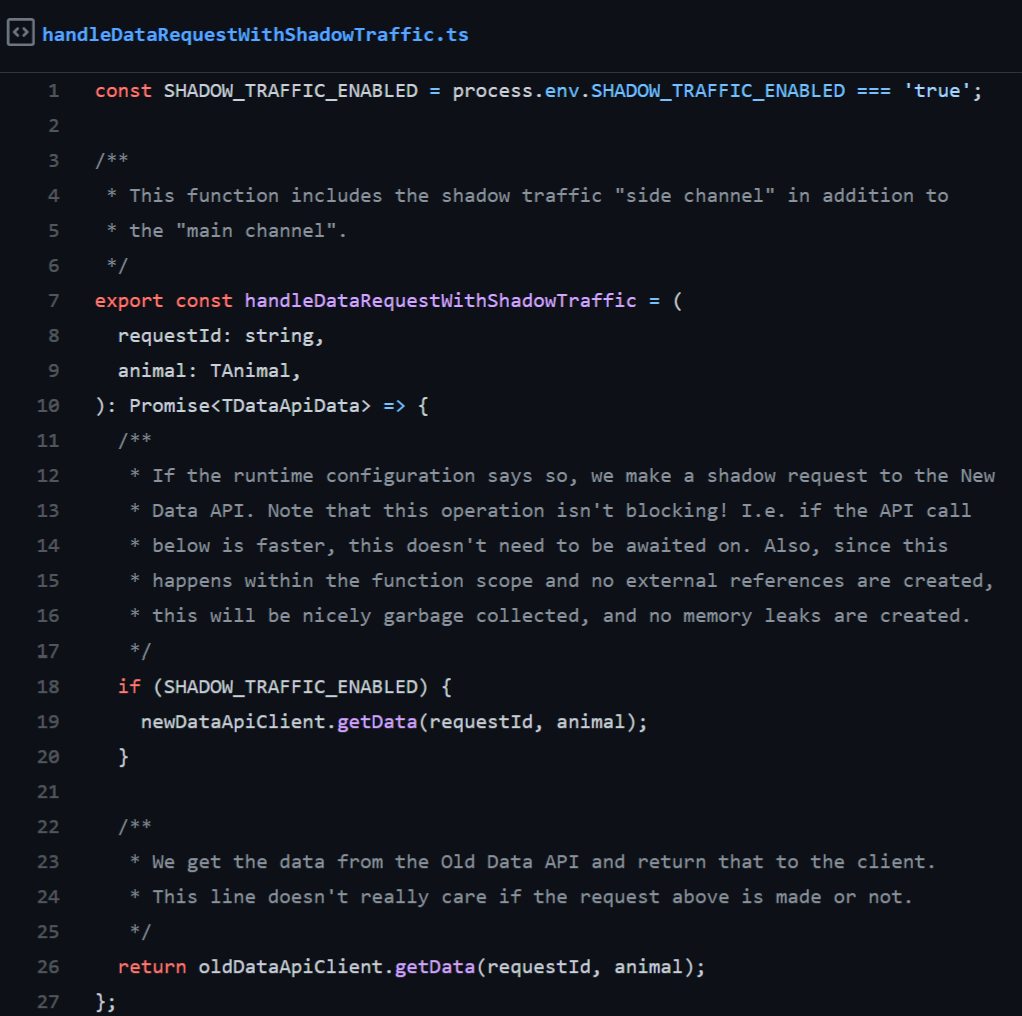
See https://github.com/futurice/shadow-and-canary-traffic-example/blob/main/src/model.ts#L18 for a full working example. Note how the same requestId is given to both clients per incoming request: this is very handy in monitoring the performance differences between Old Data API and New Data API on a per request basis. An example of how the logs could look like:
requestId: 73125a6c-e866-4029-95a9-d0d6dc0ee4d7 – SHADOW
requestId: 73125a6c-e866-4029-95a9-d0d6dc0ee4d7 – START: Requesting animal dog from New Data API
requestId: 73125a6c-e866-4029-95a9-d0d6dc0ee4d7 – START: Requesting animal dog from Old Data API
requestId: 73125a6c-e866-4029-95a9-d0d6dc0ee4d7 – REPORT: Getting animal dog took 357.8300759792328 ms from New Data API
requestId: 73125a6c-e866-4029-95a9-d0d6dc0ee4d7 – REPORT: Getting animal dog took 1358.6942350268364 ms from Old Data APIHow we benefited from traffic shadowing in our project
The real New Data API was starting to reach readiness in the feature set, and we had performed some indicative artificial load testing to tweak certain parameters. At this point we turned shadow traffic on from the production environment for the duration of around 24 hours. During this time the logs were aggregated so that we got data about the distribution of request durations. We were able to see that e.g. New Data API tended to be slower than the Old Data API for the fastest requests, but faster for the slower requests, providing a tighter duration spread.
At New Data API’s end we monitored requests and performance as well, and were able to pinpoint some problems. For example the database (AWS Redshift in this case) queries tended to get considerably slower during simultaneous data inserts, as the database resource utilization got quite high compared to other times. This led us to go after alternative solutions for data ingestion.
Like in the example code, the shadow traffic side channel was implemented so that it can be turned on or off with an environment variable. Future implications of this kind of solution could also exist. For example, once Old Data API is no longer in use and all main channel traffic goes to New Data API, we could have a side channel to the test/dev version of New Data API. This way we could try out performance improvements in test/dev (provided that it is similar to the production version) and see how they compare to the current production environment, before actually going to production and introducing potential performance regression to the users.
Example: Canary traffic
The idea of canary traffic is to split a certain portion of incoming requests to New Data API, while the rest are going to Old Data API. The client (web app) is therefore receiving data from both systems, according to a defined split.
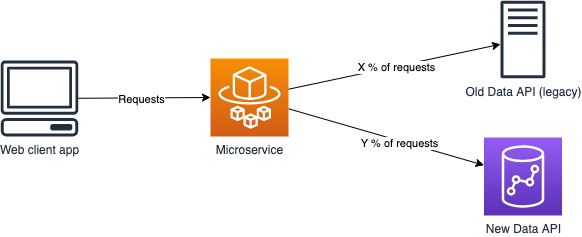
Like shadow traffic, canary traffic can also be used to test the performance of New Data API gradually, without sudden effect on users’ experience. However, the problem with this is that the full scale isn’t reached until all traffic is directed to New Data API, making shadow traffic a better candidate for actual testing.
Our implementation of application level canary was an environment variable, named CANARY_THRESHOLD_PERCENT in the example. In the old state the variable can be set to 0, meaning that all requests are directed to Old Data API. We can then gradually raise the percentage to e.g. 10, meaning that 10 percent of all requests are directed to New Data API, while the remaining 90 percent still go to Old Data API. Updating the percentage is as simple as editing the environment variable value and restarting/redeploying the service. On code level it looks like this:
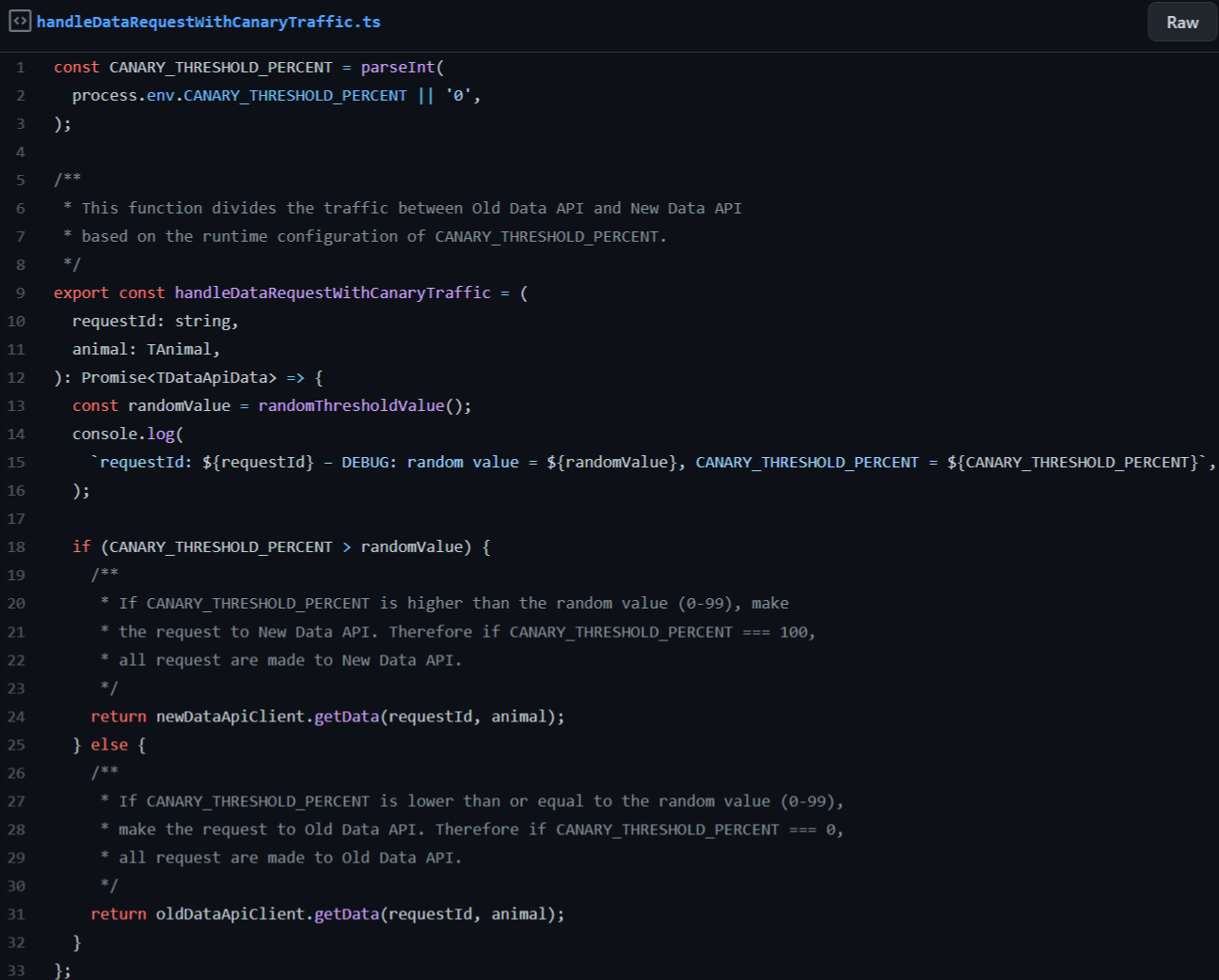
See https://github.com/futurice/shadow-and-canary-traffic-example/blob/main/src/model.ts#L48 for a full working example. This time the logs could look something like this:
requestId: b1978bb8-82ab-4b59-888f-ca53e2e3e2a9 – CANARY
requestId: b1978bb8-82ab-4b59-888f-ca53e2e3e2a9 – DEBUG: random value = 27, CANARY_THRESHOLD_PERCENT = 50
requestId: b1978bb8-82ab-4b59-888f-ca53e2e3e2a9 – START: Requesting animal cat from New Data API
requestId: b1978bb8-82ab-4b59-888f-ca53e2e3e2a9 – REPORT: Getting animal cat took 1011.1178050041199 ms from New Data APINote that traditional canary deployments are often automated: some readiness/healthiness checks or other KPIs are defined for the service, and if those pass the automated checks, the portion of traffic directed to the new service is automatically increased, until 100 % is reached. In our case the whole process is more manual because we are not deploying a new version of an existing service, but a whole new API.
How we benefited from canary traffic in our project
We are not in production as of yet, but we have been in situations where Old Data API has failed, and we have had to temporarily redirect traffic to New Data API to avoid the whole service being down. This has worked nicely, as traffic redirection is as simple as updating the environment variable value to 100%, directing all traffic to New Data API, and restarting/redeploying the service.
Once we actually go live with New Data API, we can use canary to do that incrementally in a controlled fashion, instead of deploying a single code change that needs to be rolled back if anything goes wrong. After this we can remove the canary logic from the code, which means code changes on only the model layer.
Learnings and recommendations from Nodejs shadow and canary traffic testing
Both shadow and canary traffic can be hugely beneficial in testing and ensuring the quality of your software before exposing users to potential effects. Sometimes the creative use of what you have available can go a long way, as long as you write your software in a modular and well structured way. Nodejs and TypeScript make this kind of testing easy, but the same principles can be applied to other languages and frameworks as well.
Bonus
There are solutions for recording production traffic and replaying it in a controlled fashion for testing purposes. I haven't personally tested it, but ShadowReader seems very interesting and might be helpful if you ever find yourself needing such capabilities.
 Antti PitkänenSoftware & Business Developer
Antti PitkänenSoftware & Business Developer

