Programming is fun because a programmer has the power to build any virtual experience they can imagine. It's fun until we get stuck with bugs. And we might spend up to 50% (!) of our time solving them. Overall, bug fixing costs billions of dollars per year to the software industry.
Bugs can also be very demotivating, some people quit their programming careers early on because of them. I have seen it happen.
Obviously, we all want to avoid bugs. You should write code and design architecture in a way that makes debugging unnecessary. Code should be presented in a way that makes it obvious how it works. However, ultimately it seems impossible to eliminate bugs and debugging altogether.
If we are to become better programmers, we need to master debugging.
Our goal is to stay "in the flow". Both customers and programmers want to build software as quickly as possible. No one wants to spend time with bugs. How can we overcome bugs while spending as little time as possible?
Lean is all about avoiding waste. Time is our valuable resource, so proper debugging is lean debugging.
Validate your riskiest assumptions as soon as possible
By definition, a bug is a phenomenon that we don't want. Normally, it's a phenomenon that happens for some unknown reason. If you know the reason, then fixing is normally trivial. Most of the time is, therefore, spent discovering the reason.
In the process of resolving a bug, we naturally make assumptions. We might trust the compiler, assuming it doesn't make mistakes. We might assume that we made no typos. We might assume a certain class or function is working perfectly.
How can we speed up our assumption validation and get the bug fixed as quickly as possible?
Assumption validation techniques for debugging
Systematic debugging techniques are often top-to-bottom. If you have no idea where your bug lives, you can start by blindly assuming the bug exists in one large region of your codebase, and validating whether it does or not. In other contexts, this is known as divide-and-conquer.
You can search for bugs in time or in space. When searching for the bug in time, you are trying to answer the question: "when (at which Git commit) was this bug introduced?" When searching for the bug in space, the question is "where precisely is the root of this bug in my codebase?".
For searching in time, git bisect is a known tool. It allows you to tag one state of your codebase as "good" (the bug does not occur), and another state as "bad" (bug occurs), then recursively search for the states in between until you discover the specific git commit which introduced the bug.
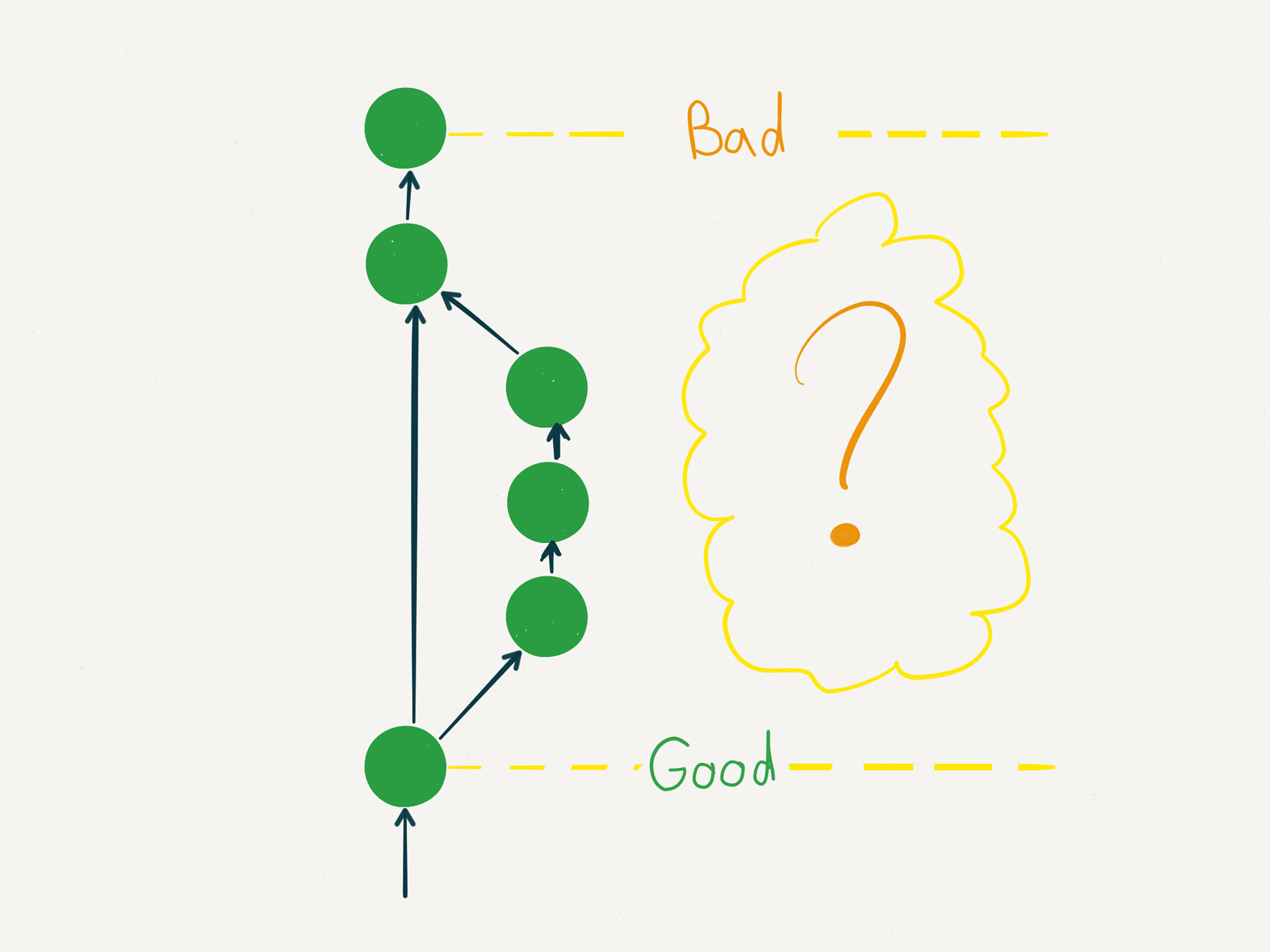 Searching a bug in time using git bisect
Searching a bug in time using git bisect
Searching bugs with git bisect is made easier if your commits are atomic changes. This is why git and its best practices are a powerful tool not only for teamwork and version control, but specially for debugging your own code. Consider using git and writing small coherent commits even when working alone.
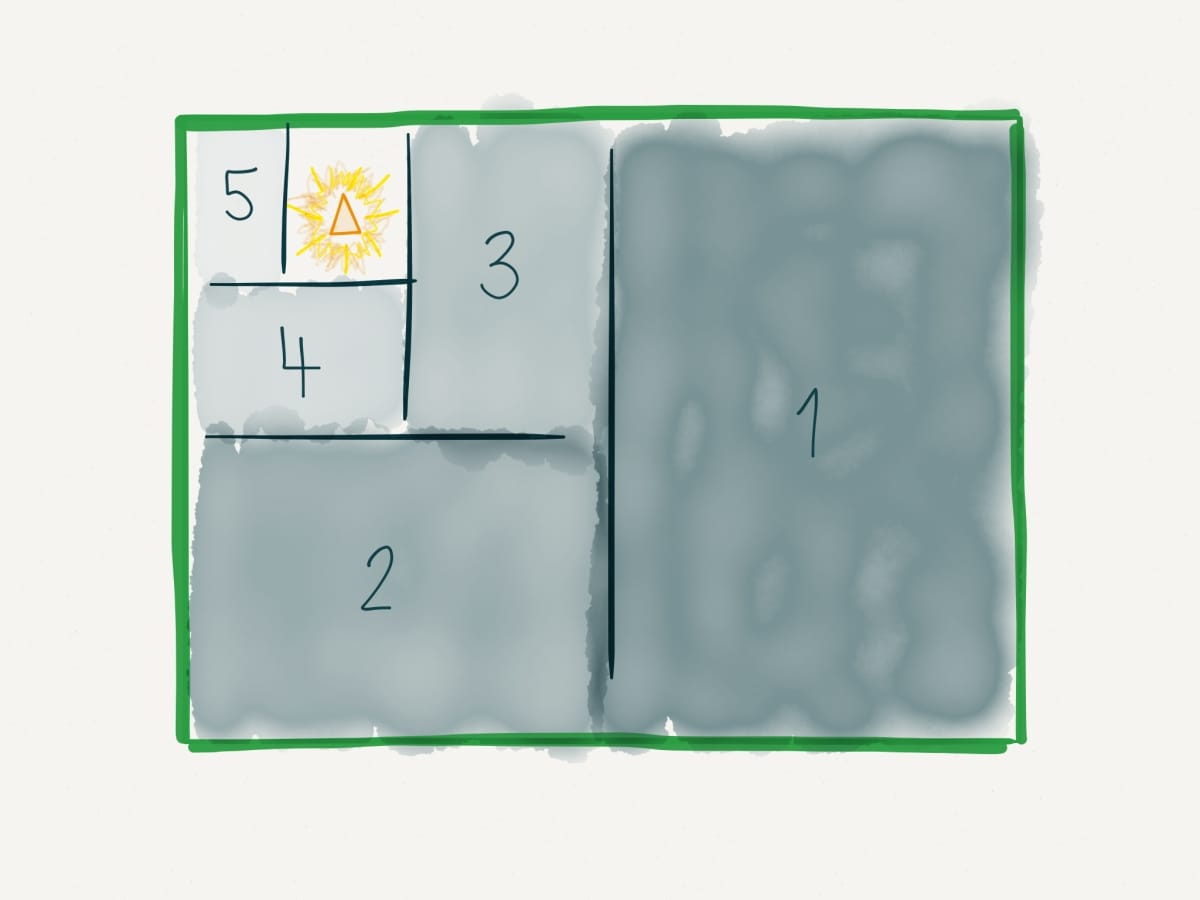
For searching in space, most programmers have done binary-search with commented code: comment out or bypass half of your codebase. Do that recursively until you nail down where (at which file, which function, which lines) the bug lives.
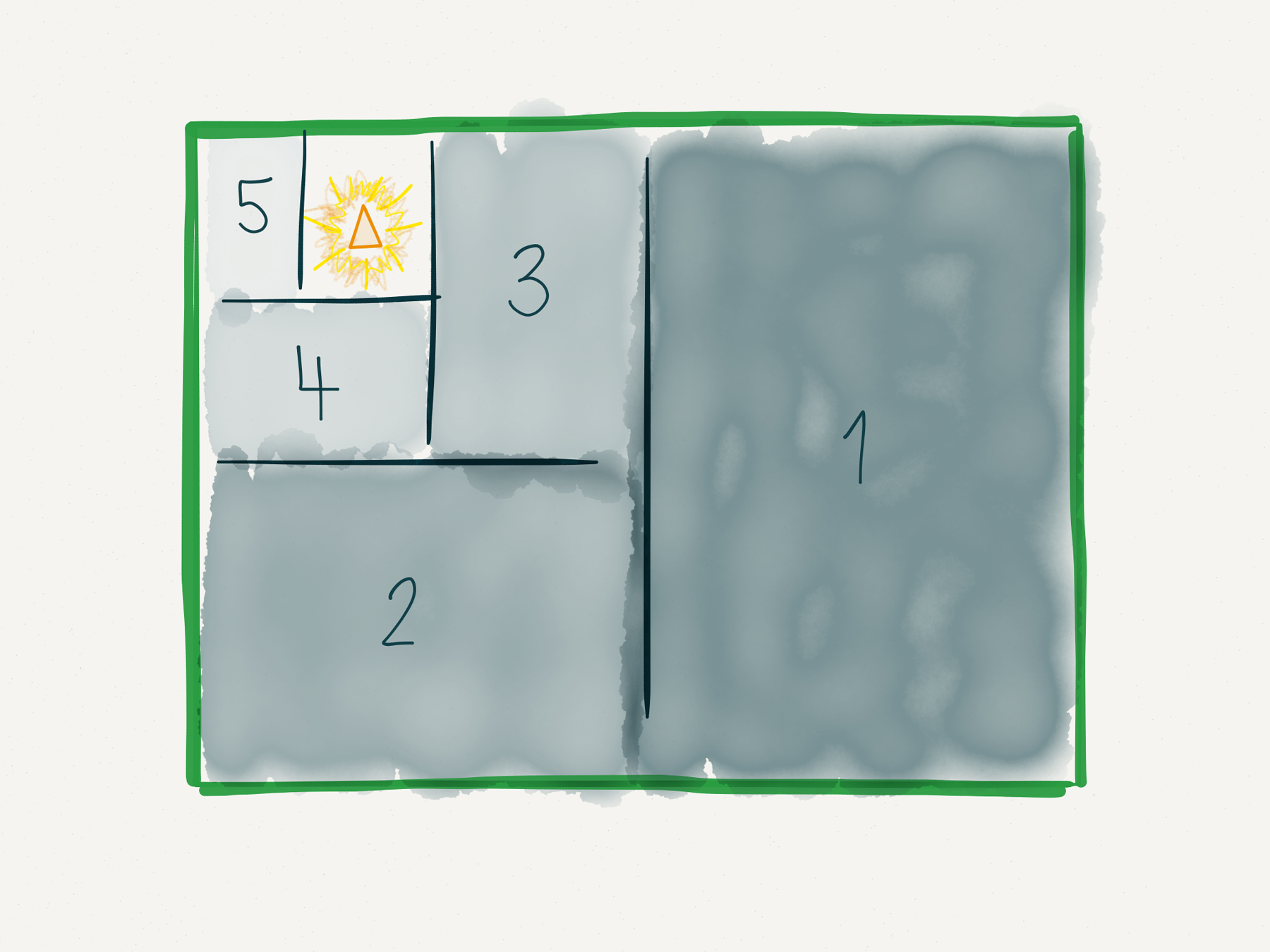 Searching for bugs in space using comments to bypass sections of code
Searching for bugs in space using comments to bypass sections of code
It's not always that simple, though. A bug might span multiple modules, requiring understanding of the whole state and control flow of those modules. In unfortunate cases, however, there is nothing wrong with your codebase. The cause for the bug might even be external to your codebase.
When binary search doesn't work, you need more creative approaches. Consider brainstorming to enumerate even the wildest possibilities: for instance, maybe the bug is in some external resource like a library or a remote service; maybe there is version mismatch of libraries; maybe your tool (e.g. IDE) has a problem; maybe it is bit flipping in the hard disk; maybe the date and time library is sensitive to your computer's settings, etc.
When validating your assumptions, your problem could also be in your validation method: you might think you have validated that there are no typos, but there actually might still be a typo. Consider validating your assumption twice with different methods. If you are in a team, do pair programming so at least two people have validated the same assumption, in different ways.
Your goal should be to validate the assumption of the PROBLEM, not to validate the assumption of the SOLUTION.
Avoid antagonizing the bug
Programmers often make the bug "the enemy", and it's not rare to swear at the computer. Programming, however, is a lot about understanding correctly, not about typing and building. Most of our programming time is spent understanding how all parts should be connected, and only a small fraction of our time is spent with actual keyboard typing.
Prefer to antagonize your lack of understanding more than the bug itself. This might sound obvious, but in the middle of debugging, you are likely to antagonize the bug. Make a conscious decision to avoid that. Once you understand everything, fixing the bug is normally a simple task.
How can you understand better and quicker?
Some programmers are geniuses and understand everything in little time. If you are like me, you do not understand a lot by just glancing at the code. You might need to run the program a couple of times and experiment with it to discover some properties of its functionality.
Debuggers are an obvious tool for understanding your program. But you can also rely on ad-hoc tools for aiding your understanding. Reading logs or using the poorer variant of printing debugging strings to the console are great tools that complement debuggers. While debuggers give you insight into deep and specific parts of your codebase, logs and console prints can help you build a bird's-eye perspective of your program. This might be useful for validating assumptions that span multiple modules.
Be creative and think outside the box to build more exotic tools than the common ones. RxVision is one example for reactive programming. Build them yourself or search the web for others. Don't shy away from spending time building tools for improving your understanding of the code, and remember that bugs cost billions to the software industry.
Preventing bugs
Because programming is understanding, preventing bugs is often related to proper architecture which makes it easier to reason about the program's functionality. There is a lot of ongoing discussion on which programming model and architectures are the best, but some practices are widely recommended.
One of these ubiquitous practices is to keep different levels of abstraction separated. Here is one simple example in Kotlin:
fun getEuroString(value: Number): String {
// if is decimal currency value
if (Math.abs(value.toDouble() - value.toInt().toDouble()) >= 0.01) {
val decimalValue = "%.2f".format(value).replace("\\.\\d+", "")
return "$decimalValue $EURO_SYMBOL"
} else {
return getIntegerEuroString(value.toInt())
}
}This getEuroString() function checks if the given number is not an integer, returning a price label in euros with two decimal digits, otherwise returning a price label with a whole value. This function works, but has a problem: the condition in the if is working on a lower abstraction level than the rest of the control flow. This function should only express the logic we mentioned above, yet it goes into details which are irrelevant to its purpose.
The function might be a source of bugs and an obstacle during debugging in the future. The reason for that is: while debugging, it is likely you will look getEuroString() through the perspective of one level of abstraction ("it checks if the value is a decimal, to use the decimal format, otherwise uses the integer format") and dismiss the lower levels of abstraction, assuming they are correctly doing what you want them to do. And that is where the problem is: letting an assumption slip away unchecked.
Instead, we should refactor the function so that it uses other functions which hide those lower level instructions.
fun getEuroString(value: Number): String {
if (isDecimal(value)) {
return getDecimalEuroString(value.toDouble())
} else {
return getIntegerEuroString(value.toInt())
}
}
fun isDecimal(value: Number): Boolean {
return Math.abs(value.toDouble() - value.toInt().toDouble()) >= 0.01
}
fun getIntegerEuroString(value: Int): String {
return "$value $EURO_SYMBOL"
}
fun getDecimalEuroString(value: Double): String {
val decimalValue = "%.2f".format(value).replace("\\.\\d+", "")
return "$decimalValue $EURO_SYMBOL"
}In this fashion, you facilitate the assumption validation process when debugging: when inspecting getIntegerEuroString() or any other function, it will be straightforward to check whether it only does what it says it does. Each function makes it obvious on which level of abstraction it operates, so you don't need to mentally switch between different levels of abstraction when inspecting the function. It focuses your mind, pointing you in the right direction for hunting bugs.
Overall, programming practices that prevent bugs are empathic to other programmers and to your future self. Code which looks obvious and looks easy to read and change is code which eventually yields less bugs.
"Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it."— Brian Kernighan
The takeaway
To prevent bugs, write code that looks easy in any programmer's eyes. To fix bugs, understand your code. To understand your code with precision, enumerate and validate your assumptions, building debugging tools if necessary.
 Andre MedeirosUser Interface Engineer
Andre MedeirosUser Interface Engineer


